Что такое MD5. Хеширование и расшифровка MD5 хеш-кода Как расшифровать MD5-хэш: общие принципы
 Live Journal
Live Journal Facebook
Facebook Twitter
TwitterМного на просторах интернета, в том числе на хабре , написано о различный хэш-функциях, однако, в данном топике я дам свой взгляд на алгоритм и реализацию MD5.
Что такое хэш-функция и чем её едят?
Хэш-функция предназначена для свертки входного массива любого размера в битовую строку, для MD5 длина выходной строки равна 128 битам. Для чего это нужно? К примеру у вас есть два массива, а вам необходимо быстро сравнить их на равенство, то хэш-функция может сделать это за вас, если у двух массивов хэши разные, то массивы гарантировано разные, а в случае равенства хэшей - массивы скорее всего равны.Однако чаще всего хэш-функции используются для проверки уникальности пароля, файла, строки и тд. К примеру, скачивая файл из интернета, вы часто видите рядом с ним строку вида - это и есть хэш, прогнав этот файл через алгоритм MD5 вы получите такую строку, и, если хэши равны, можно с большой вероятностью утверждать что этот файл действительно подлинный (конечно с некоторыми оговорками, о которых расскажу далее).
Конкретнее о MD5
Не буду углубляться в историю создания, об этом можно почитать в википедии, однако отмечу что алгоритм был создан профессором Р. Риверстом в 1991 году на основе алгоритма md4. Описан этот алгоритм в RFC 1321Алгоритм состоит из пяти шагов:
1)Append Padding Bits
В исходную строку дописывают единичный байт 0х80, а затем дописывают нулевые биты, до тех пор, пока длина сообщения не будет сравнима с 448 по модулю 512. То есть дописываем нули до тех пор, пока длина нового сообщения не будет равна [длина] = (512*N+448),
где N - любое натуральное число, такое, что это выражение будет наиболее близко к длине блока.
2)Append Length
Далее в сообщение дописывается 64-битное представление длины исходного сообщения.
3)Initialize MD Buffer
На этом шаге инициализируется буффер
word A: 01 23 45 67
word B: 89 ab cd ef
word C: fe dc ba 98
word D: 76 54 32 10
Как можно заметить буффер состоит из четырех констант, предназначенный для сбора хэша.
4)Process Message in 16-Word Blocks
На четвертом шаге в первую очередь определяется 4 вспомогательные логические функции, которые преобразуют входные 32-битные слова, в, как ни странно, в 32-битные выходные.
F(X,Y,Z) = XY v not(X) Z
G(X,Y,Z) = XZ v Y not(Z)
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X v not(Z))
Также на этом шаге реализуется так называемый «белый шум» - усиление алгоритма, состоящее 64 элементного массива, содержащего псевдослучайные числа, зависимые от синуса числа i:
T[i]=4,294,967,296*abs(sin(i))
Далее начинается «магия». Копируем каждый 16-битный блок в массив X и производим манипуляции:
AA = A
BB = B
CC = C
DD = D
Затем происходят «чудесные» преобразования-раунды, которых всего будет 4. Каждый раунд состоит из 16 элементарных преобразований, которые в общем виде можно представить в виде , которое, в свою очередь, можно представить как A = B + ((A + F(B,C,D) + X[k] + T[i]) <<< s), где
A, B, C, D - регистры
F(B,C,D) - одна из логических функций
X[k] - k-тый элемент 16-битного блока.
T[i] - i-тый элемент таблицы «белого шума»
<<< s - операция циклического сдвига на s позиций влево.
Приводить все раунды не имеет смысла, все их можно посмотреть
Ну и в конце суммируем результаты вычислений:
A = A + AA
B = B + BB
C = C + CC
D = D + DD
5) Output
Выводя побайтово буффер ABCD начиная с A и заканчивая D получим наш хэш.
Надежность
Существует мнение что взломать хэш MD5 невозможно, однако это неправда, существует множество программ подбирающих исходное слово на основе хэша. Абсолютное большинство из них осуществляет перебор по словарю, однако существуют такие методы как RainbowCrack , он основан на генерировании множества хэшей из набора символов, чтобы по получившейся базе производить поиск хэша.Также у MD5, как у любой хэш-функции, существует такое понятие как коллизии - это получение одинаковых хэшей для разных исходных строк. В 1996 году Ганс Доббертин нашёл псевдоколлизии в MD5, используя определённый инициализирующий буффер (ABCD). Также в 2004 году китайские исследователи Ван Сяоюнь, Фен Дэнгуо, Лай Сюэцзя и Юй Хунбо объявили об обнаруженной ими уязвимости в алгоритме, позволяющей за небольшое время (1 час на кластере IBM p690) находить коллизии. Однако в 2006 году чешский исследователь Властимил Клима опубликовал алгоритм, позволяющий находить коллизии на обычном компьютере с любым начальным вектором (A,B,C,D) при помощи метода, названного им «туннелирование».
Прилагаю собственный пример реализации функции на C#:
md5.rar
Теги: криптография, md5
Данная статья не подлежит комментированию, поскольку её автор ещё не является полноправным участником сообщества. Вы сможете связаться с автором только после того, как он получит приглашение от кого-либо из участников сообщества. До этого момента его username будет скрыт псевдонимом.
MD5 или Message Digest 5 это 128-битный алгоритм хеширования разработанный в начале 90-х годов профессором Рональдом Ривестом. Как правило, представляется как последовательность из 32 шестнадцатеричных цифр, например:. Для того чтобы понять что такое MD5 сначала нужно разобраться с понятием хеширование.
Хеширование это процесс преобразования любого массива данных в выходную строку фиксированной длины. Это преобразование проводится с помощью, так называемых, хеш-функций. Такая функция на входе получает массив данных, а на выходе возвращает так называемый хеш (хеш-суму) – уникальную строку фиксированной длины.
Алгоритм работы хеш-функции построен таким образом, что для любого массива данных функция выдает уникальную строку. Благодаря этой особенности полученная строка может использоваться как цифровой отпечаток данных. Такой отпечаток можно использовать для проверки целостности данных.
Например, когда разработчик программного обеспечения публикует в сети свой программный продукт, вместе с ним он может опубликовать его хеш. Это позволит пользователям проверить целостность программы перед ее установкой. Ели программа была заражена вирусами или загрузилась с ошибками, ее хеш не будет соответствовать хешу, который был опубликован разработчиком программы.
История развития MD5
Алгоритм MD5 был разработан профессором Рональдом Л. Ривестом из Массачусетского технологического института в 1991 году. Данный алгоритм стал заменой предыдущей версии алгоритма MD4. С этого времени алгоритм обрел большую популярность и стал использоваться повсеместно.
Начиная с 1993 года, регулярно появляются исследования, которые обнаруживают все новые уязвимости в алгоритме MD5. На данный момент алгоритм MD5 считается уязвимым и постепенно заменяется алгоритмом SHA.
Как получить хеш MD5
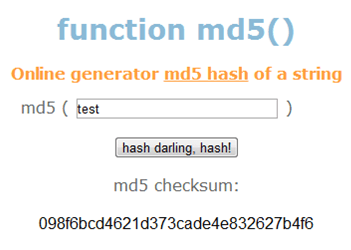
Если вам необходимо получить MD5 хеш от обычной строки текста, то удобней всего использовать онлайн сервисы. Одним из таких сервисов является .
Для того чтобы получить MD5 хеш с помощью этого сервиса достаточно ввести строку в поле и нажать на кнопку «Hash». Поле этого появится хеш введенной строки.
Если же вам нужно получить MD5 хеш файла, то придётся использовать специальные программы, например, MD5summer (
Песочница
Лунтик 27 марта 2011 в 16:59Хэш-функция MD5
- Чулан *
Много на просторах интернета, в том числе , написано о различный хэш-функциях, однако, в данном топике я дам свой взгляд на алгоритм и реализацию MD5.
Что такое хэш-функция и чем её едят?
Хэш-функция предназначена для свертки входного массива любого размера в битовую строку, для MD5 длина выходной строки равна 128 битам. Для чего это нужно? К примеру у вас есть два массива, а вам необходимо быстро сравнить их на равенство, то хэш-функция может сделать это за вас, если у двух массивов хэши разные, то массивы гарантировано разные, а в случае равенства хэшей - массивы скорее всего равны.Однако чаще всего хэш-функции используются для проверки уникальности пароля, файла, строки и тд. К примеру, скачивая файл из интернета, вы часто видите рядом с ним строку вида - это и есть хэш, прогнав этот файл через алгоритм MD5 вы получите такую строку, и, если хэши равны, можно с большой вероятностью утверждать что этот файл действительно подлинный (конечно с некоторыми оговорками, о которых расскажу далее).
Конкретнее о MD5
Не буду углубляться в историю создания, об этом можно почитать в википедии, однако отмечу что алгоритм был создан профессором Р. Риверстом в 1991 году на основе алгоритма md4. Описан этот алгоритм в RFC 1321Алгоритм состоит из пяти шагов:
1)Append Padding Bits
В исходную строку дописывают единичный байт 0х80, а затем дописывают нулевые биты, до тех пор, пока длина сообщения не будет сравнима с 448 по модулю 512. То есть дописываем нули до тех пор, пока длина нового сообщения не будет равна [длина] = (512*N+448),
где N - любое натуральное число, такое, что это выражение будет наиболее близко к длине блока.
2)Append Length
Далее в сообщение дописывается 64-битное представление длины исходного сообщения.
3)Initialize MD Buffer
На этом шаге инициализируется буффер
word A: 01 23 45 67
word B: 89 ab cd ef
word C: fe dc ba 98
word D: 76 54 32 10
Как можно заметить буффер состоит из четырех констант, предназначенный для сбора хэша.
4)Process Message in 16-Word Blocks
На четвертом шаге в первую очередь определяется 4 вспомогательные логические функции, которые преобразуют входные 32-битные слова, в, как ни странно, в 32-битные выходные.
F(X,Y,Z) = XY v not(X) Z
G(X,Y,Z) = XZ v Y not(Z)
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X v not(Z))
Также на этом шаге реализуется так называемый «белый шум» - усиление алгоритма, состоящее 64 элементного массива, содержащего псевдослучайные числа, зависимые от синуса числа i:
T[i]=4,294,967,296*abs(sin(i))
Далее начинается «магия». Копируем каждый 16-битный блок в массив X и производим манипуляции:
AA = A
BB = B
CC = C
DD = D
Затем происходят «чудесные» преобразования-раунды, которых всего будет 4. Каждый раунд состоит из 16 элементарных преобразований, которые в общем виде можно представить в виде , которое, в свою очередь, можно представить как A = B + ((A + F(B,C,D) + X[k] + T[i]) <<< s), где
A, B, C, D - регистры
F(B,C,D) - одна из логических функций
X[k] - k-тый элемент 16-битного блока.
T[i] - i-тый элемент таблицы «белого шума»
<<< s - операция циклического сдвига на s позиций влево.
Приводить все раунды не имеет смысла, все их можно посмотреть
Ну и в конце суммируем результаты вычислений:
A = A + AA
B = B + BB
C = C + CC
D = D + DD
5) Output
Выводя побайтово буффер ABCD начиная с A и заканчивая D получим наш хэш.
Надежность
Существует мнение что взломать хэш MD5 невозможно, однако это неправда, существует множество программ подбирающих исходное слово на основе хэша. Абсолютное большинство из них осуществляет перебор по словарю, однако существуют такие методы как RainbowCrack , он основан на генерировании множества хэшей из набора символов, чтобы по получившейся базе производить поиск хэша.Также у MD5, как у любой хэш-функции, существует такое понятие как коллизии - это получение одинаковых хэшей для разных исходных строк. В 1996 году Ганс Доббертин нашёл псевдоколлизии в MD5, используя определённый инициализирующий буффер (ABCD). Также в 2004 году китайские исследователи Ван Сяоюнь, Фен Дэнгуо, Лай Сюэцзя и Юй Хунбо объявили об обнаруженной ими уязвимости в алгоритме, позволяющей за небольшое время (1 час на кластере IBM p690) находить коллизии. Однако в 2006 году чешский исследователь Властимил Клима опубликовал алгоритм, позволяющий находить коллизии на обычном компьютере с любым начальным вектором (A,B,C,D) при помощи метода, названного им «туннелирование».
Прилагаю собственный пример реализации функции на C#:
md5.rar
Теги: криптография, md5
Данная статья не подлежит комментированию, поскольку её автор ещё не является полноправным участником сообщества. Вы сможете связаться с автором только после того, как он получит приглашение от кого-либо из участников сообщества. До этого момента его username будет скрыт псевдонимом.
В этой статье я решил затронуть тему MD5 хэширования , так как тема эта очень простая, интересная и очень-очень важная. Самый простой пример использования MD5 хэша - это шифрование паролей пользователей. Ведь не секрет, что если хранить пароли в открытом виде в базе данных, то при её утере, все пароли пользователей будут украдены, чего не имеет никакого морального права допустить администратор. И вот тут на помощь приходит функция хэширования в PHP .
Функция MD5 хэширования в PHP называется md5() . Принимает функция одну строку, которую необходимо зашифровать. Функция возвращает MD5 хэш :
$str = "MyPassword";
echo md5($str);
?>
Запустив данный скрипт, Вы увидите MD5-хэш , соответствующий строке "MyPassword ".
То есть простейший скрипт проверки логина и пароля:
$login = "Admin";
$password = "48503dfd58720bd5ff35c102065a52d7"; //В реальности считывается из БД
if (($_GET["login"] == $login) && (md5($_GET["password"]) == $password)) echo "Welcome!";
else echo "Access denied";
?>
Теперь поговорим о свойствах MD5-хэширования .
- MD5-хэш содержит 32 символа
- MD5-хэш уникален для каждой строки
- Процесс MD5-хэширования необратим
- Процесс MD5-хэширования достаточно медлителен
Третий пункт, пожалуй, самый важный, потому что если бы он был обратим, то смысл хэширования практически бы отсутствовал. Глупо шифровать, например, пароли, если их можно легко потом расшифровать.
Четвёртый пункт, как бы это парадоксально не звучало, также является очень большим плюсом. Почему? Очень просто: человек, который будет вынужден подождать этот процесс 0.001 секунды, сильно не пострадает. А вот злоумышленник, который будет перебирать пароли пострадает резко, так как медлительность алгоритма уже задаёт предел - 1000 паролей в секунду. Хотя, безусловно, скорость зависит от быстродействия сервера. Но тем не менее, для злоумышленника низкая скорость получения MD5-хэша - это очень большая проблема.
На будущее: никогда не храните пароли в открытом виде, забудьте об этом раз и навсегда. Поэтому всегда отправляйте пароли в базу данных в виде MD5-хэша , и, соответственно, сравнивайте хэши паролей, а не сами пароли.
- Установка PHP под ОС Windows Установка php 5 3
- Подключение внешних файлов
- Хеширование и расшифровка MD5 хеш-кода Как расшифровать MD5-хэш: общие принципы
- Соревнования по программированию Отключение XML-RPC в шаблоне
- VLC Media Player скачать бесплатно для windows русская версия Скачать vlc русская версия
- Полная чистка компьютера от мусора: подробная инструкция
- Huawei HG8245h: характеристики, настройка роутера, прошивка